独自の RAG アプリを構築する: Ollama、Python、ChromaDB を使用して LLM をローカルでセットアップするためのステップバイステップ ガイド
in Vlog
データのプライバシーが何よりも重要視される時代において、独自のローカル言語モデル (LLM) を設定することは、企業にとっても個人にとっても重要なソリューションとなります。このチュートリアルは、システム上でローカルにホストされている Ollama、Python 3、ChromaDB を使用してカスタム チャットボットを作成するプロセスをガイドするように設計されています。このチュートリアルが必要な主な理由は次のとおりです。
- 完全なカスタマイズ: 独自の Retrieval-Augmented Generation (RAG) アプリケーションをローカルでホストすると、セットアップとカスタマイズを完全に制御できます。外部サービスに頼ることなく、特定のニーズに合わせてモデルを微調整できます。
- プライバシーの強化: LLM モデルをローカルに設定することで、機密データをインターネット経由で送信することに伴うリスクを回避できます。これは、機密情報を扱う企業にとって特に重要です。プライベート データを使用してモデルをローカルでトレーニングすることで、データが常に管理下に置かれます。
- データ セキュリティ: サードパーティの LLM モデルを使用すると、データが侵害や不正使用の危険にさらされる可能性があります。ローカル展開では、PDF ドキュメントなどのトレーニング データを安全な環境内に保持することで、これらのリスクを軽減します。
- データ処理の制御: 独自の LLM をホストすると、データを希望どおりに管理および処理できるようになります。これには、プライベート データを ChromaDB ベクター ストアに埋め込むことが含まれており、データ処理が標準と要件を満たしていることが保証されます。
- インターネット接続からの独立: チャットボットをローカルで実行すると、インターネット接続に依存しなくなります。これにより、オフラインのシナリオでも、チャットボットへの中断のないサービスとアクセスが保証されます。
このチュートリアルでは、プライバシーや制御を損なうことなく、ニーズに合わせてカスタマイズされた堅牢で安全なローカル チャットボットを構築できるようになります。

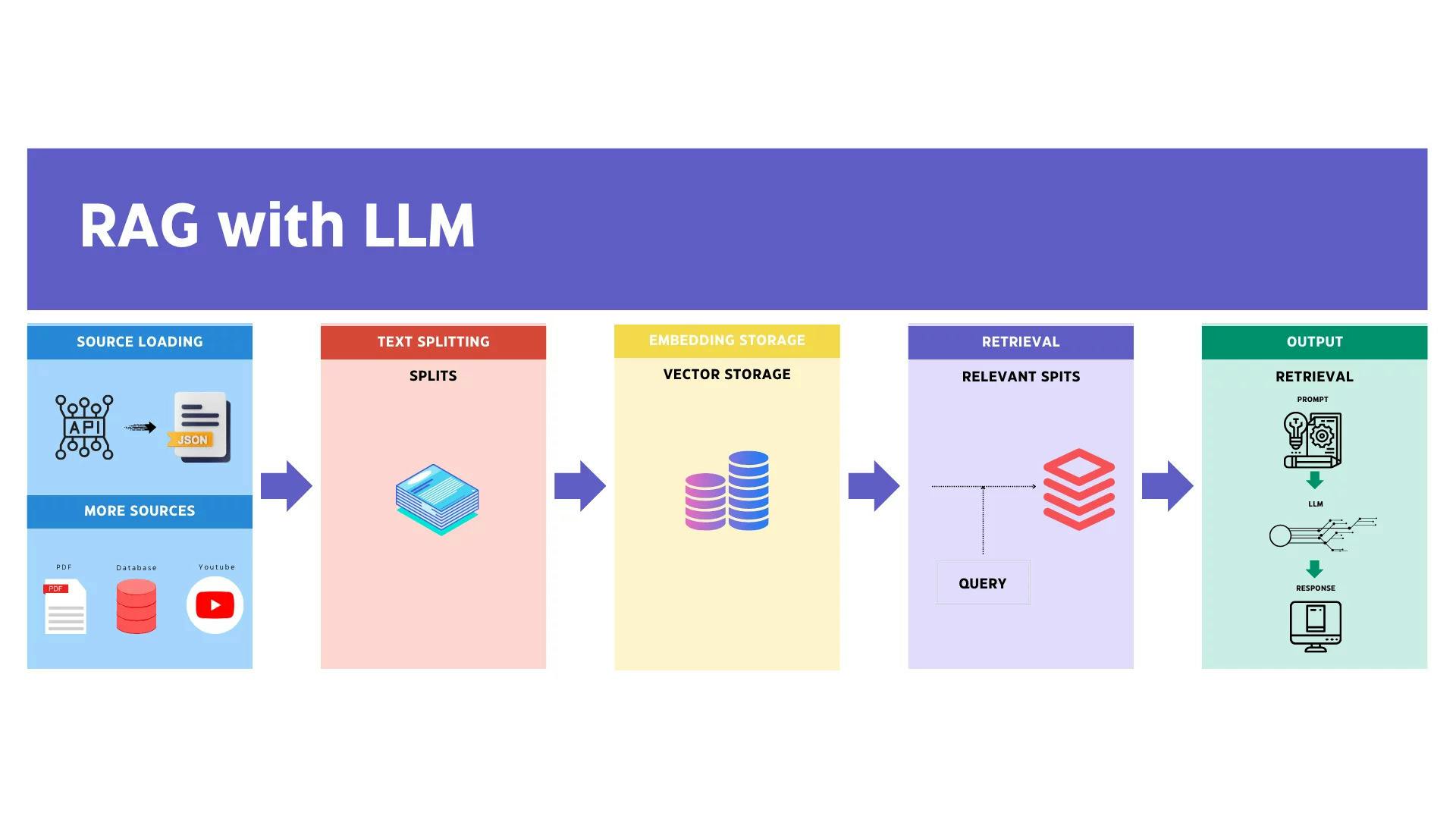
検索拡張生成 (RAG)
検索拡張生成 (RAG) は、情報検索とテキスト生成の長所を組み合わせて、より正確で文脈に即した応答を作成する高度な技術です。RAG の仕組みとその利点について、以下に詳しく説明します。
RAGとは何ですか?
RAG は、外部の知識ベースまたはドキュメント ストアを組み込むことで言語モデルの機能を強化するハイブリッド モデルです。このプロセスには、次の 2 つの主要コンポーネントが含まれます。
- 検索: このフェーズでは、モデルは入力クエリに基づいて、データベースやベクター ストアなどの外部ソースから関連するドキュメントまたは情報を取得します。
- 生成: 取得された情報は生成言語モデルによって使用され、一貫性があり文脈に適した応答が生成されます。
RAG はどのように機能しますか?
- クエリ入力: ユーザーがクエリまたは質問を入力します。
- ドキュメントの取得: システムはクエリを使用して外部のナレッジ ベースを検索し、最も関連性の高いドキュメントまたは情報のスニペットを取得します。
- 応答生成: 生成モデルは取得した情報を処理し、それを独自の知識と統合して、詳細かつ正確な応答を生成します。
- 出力: ナレッジ ベースからの具体的かつ関連性の高い詳細情報が追加された最終応答がユーザーに表示されます。
RAGの利点
- 精度の向上: 外部データを活用することで、RAG モデルは、特にドメイン固有のクエリに対して、より正確で詳細な回答を提供できます。
- コンテキストの関連性: 検索コンポーネントにより、生成された応答が関連性のある最新の情報に基づいていることが保証され、応答の全体的な品質が向上します。
- スケーラビリティ: RAG システムは、膨大な量のデータを組み込むように簡単に拡張できるため、幅広いクエリやトピックを処理できます。
- 柔軟性: これらのモデルは、外部の知識ベースを更新または拡張するだけでさまざまなドメインに適応できるため、汎用性が高くなります。
ローカルで RAG を使用する理由
- プライバシーとセキュリティ: RAG モデルをローカルで実行すると、外部サーバーに送信する必要がないため、機密データが安全かつプライベートに保たれます。
- カスタマイズ: 独自のデータ ソースの統合など、特定のニーズに合わせて取得および生成プロセスをカスタマイズできます。
- 独立性: ローカル セットアップにより、インターネットに接続していなくてもシステムが稼働し続け、一貫性のある信頼性の高いサービスが提供されます。
Ollama、Python、ChromaDB などのツールを使用してローカル RAG アプリケーションを設定すると、データとカスタマイズ オプションを制御しながら、高度な言語モデルの利点を享受できます。
グラフィックプロセッサ
検索拡張生成 (RAG) で使用されるような大規模言語モデル (LLM) を実行するには、かなりの計算能力が必要です。これらのモデルでデータを効率的に処理して埋め込むための重要なコンポーネントの 1 つが、グラフィックス プロセッシング ユニット (GPU) です。このタスクに GPU が不可欠な理由と、GPU がローカル LLM セットアップのパフォーマンスに与える影響について、次に説明します。
GPUとは何ですか?
GPU は、画像や動画のレンダリングを高速化するために設計された特殊なプロセッサです。順次処理タスクに最適化された中央処理装置 (CPU) とは異なり、GPU は並列処理に優れています。このため、GPU は機械学習やディープラーニング モデルに必要な複雑な数学的計算に特に適しています。
LLM にとって GPU が重要な理由
- 並列処理能力: GPU は数千の操作を同時に処理できるため、LLM でのトレーニングや推論などのタスクを大幅に高速化できます。この並列処理は、大規模なデータセットの処理やリアルタイムでの応答の生成に伴う大きな計算負荷にとって非常に重要です。
- 大規模モデルの処理効率: RAG で使用されるような LLM には、大量のメモリと計算リソースが必要です。GPU には高帯域幅メモリ (HBM) と複数のコアが搭載されており、これらのモデルに必要な大規模な行列乗算とテンソル演算を管理できます。
- より高速なデータの埋め込みと取得: ローカル RAG 設定では、ChromaDB などのベクター ストアにデータを埋め込み、関連するドキュメントをすばやく取得することがパフォーマンス向上に不可欠です。高性能 GPU はこれらのプロセスを高速化し、チャットボットが迅速かつ正確に応答できるようにします。
- トレーニング時間の短縮: LLM のトレーニングには、数百万 (または数十億) のパラメータの調整が含まれます。GPU を使用すると、CPU と比較してこのトレーニング フェーズに必要な時間を大幅に短縮できるため、モデルをより頻繁に更新および改良できます。
適切なGPUの選択
ローカル LLM を設定する場合、GPU の選択はパフォーマンスに大きな影響を与える可能性があります。考慮すべき要素は次のとおりです。
- メモリ容量: モデルが大きいほど、より多くの GPU メモリが必要になります。大規模なデータセットとモデル パラメータに対応するには、より高い VRAM (ビデオ RAM) を備えた GPU を探してください。
- 計算能力: GPU の CUDA コアの数が多いほど、並列処理タスクをより効率的に処理できます。計算能力の高い GPU は、ディープラーニング タスクに効果的です。
- 帯域幅: メモリ帯域幅が広いほど、GPU とメモリ間のデータ転送が高速化され、全体的な処理速度が向上します。
LLM 向け高性能 GPU の例
- NVIDIA RTX 3090: 大容量の VRAM (24 GB) と強力な CUDA コアで知られ、ディープラーニング タスクに人気の選択肢です。
- NVIDIA A100: AI と機械学習向けに特別に設計されており、大容量のメモリと高い計算能力により優れたパフォーマンスを提供します。
- AMD Radeon Pro VII: 高いメモリ帯域幅と効率的な処理能力を備えた、もう 1 つの強力な候補です。
高性能 GPU への投資は、LLM モデルをローカルで実行するために不可欠です。これにより、データ処理の高速化、モデルの効率的なトレーニング、応答の迅速な生成が保証され、ローカル RAG アプリケーションの堅牢性と信頼性が向上します。GPU のパワーを活用することで、特定のニーズとデータ プライバシー要件に合わせてカスタマイズされた独自のカスタム チャットボットをホストするメリットを十分に実現できます。
前提条件
セットアップに進む前に、次の前提条件が満たされていることを確認してください。
- Python 3: Python は、RAG アプリのコードを記述するために使用する多目的プログラミング言語です。
- ChromaDB: データの埋め込みを保存および管理するベクター データベース。
- Ollama: ローカル マシンにカスタム LLM をダウンロードして提供します。
ステップ1: Python 3をインストールして環境を設定する
Python 3 環境をインストールして設定するには、次の手順に従ってください: マシンに Python 3 をダウンロードして設定します。次に、Python 3 が正常にインストールされ、実行されていることを確認します。
$ python3 --version
# Python 3.11.7
プロジェクト用のフォルダを作成します。たとえば、 local-rag:
$ mkdir local-rag
$ cd local-rag
仮想環境を作成します venv:
$ python3 -m venv venv
仮想環境をアクティブ化します。
$ source venv/bin/activate
# Windows
# venv\Scripts\activate
ステップ2: ChromaDBとその他の依存関係をインストールする
pip を使用して ChromaDB をインストールします。
$ pip install --q chromadb
モデルをシームレスに操作するには、Langchain ツールをインストールします。
$ pip install --q unstructured langchain langchain-text-splitters
$ pip install --q "unstructured(all-docs)"
アプリを HTTP サービスとして提供するには、Flask をインストールします。
$ pip install --q flask
ステップ3: Ollamaをインストールする
Ollama をインストールするには、次の手順に従います。Ollama のダウンロード ページにアクセスし、お使いのオペレーティング システム用のインストーラーをダウンロードします。次のコマンドを実行して、Ollama のインストールを確認します。
$ ollama --version
# ollama version is 0.1.47
必要な LLM モデルを取得します。たとえば、Mistral モデルを使用する場合は、次のようにします。
$ ollama pull mistral
テキスト埋め込みモデルを取得します。たとえば、Nomic Embed Text モデルを使用するには、次のようにします。
$ ollama pull nomic-embed-text
次に、Ollama モデルを実行します。
$ ollama serve
RAGアプリを構築する
Python、Ollama、ChromaDB、その他の依存関係を使用して環境をセットアップしたので、次はカスタム ローカル RAG アプリを構築します。このセクションでは、実践的な Python コードを確認し、アプリケーションを構築する方法の概要を説明します。
app.py
これはメインの Flask アプリケーション ファイルです。ベクター データベースにファイルを埋め込み、モデルから応答を取得するためのルートを定義します。
import os
from dotenv import load_dotenv
load_dotenv()
from flask import Flask, request, jsonify
from embed import embed
from query import query
from get_vector_db import get_vector_db
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
os.makedirs(TEMP_FOLDER, exist_ok=True)
app = Flask(__name__)
@app.route('/embed', methods=('POST'))
def route_embed():
if 'file' not in request.files:
return jsonify({"error": "No file part"}), 400
file = request.files('file')
if file.filename == '':
return jsonify({"error": "No selected file"}), 400
embedded = embed(file)
if embedded:
return jsonify({"message": "File embedded successfully"}), 200
return jsonify({"error": "File embedded unsuccessfully"}), 400
@app.route('/query', methods=('POST'))
def route_query():
data = request.get_json()
response = query(data.get('query'))
if response:
return jsonify({"message": response}), 200
return jsonify({"error": "Something went wrong"}), 400
if __name__ == '__main__':
app.run(host="0.0.0.0", port=8080, debug=True)
embed.py
このモジュールは、アップロードされたファイルの保存、データの読み込みと分割、ベクター データベースへのドキュメントの追加などの埋め込みプロセスを処理します。
import os
from datetime import datetime
from werkzeug.utils import secure_filename
from langchain_community.document_loaders import UnstructuredPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from get_vector_db import get_vector_db
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
# Function to check if the uploaded file is allowed (only PDF files)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)(1).lower() in {'pdf'}
# Function to save the uploaded file to the temporary folder
def save_file(file):
# Save the uploaded file with a secure filename and return the file path
ct = datetime.now()
ts = ct.timestamp()
filename = str(ts) + "_" + secure_filename(file.filename)
file_path = os.path.join(TEMP_FOLDER, filename)
file.save(file_path)
return file_path
# Function to load and split the data from the PDF file
def load_and_split_data(file_path):
# Load the PDF file and split the data into chunks
loader = UnstructuredPDFLoader(file_path=file_path)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=7500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
return chunks
# Main function to handle the embedding process
def embed(file):
# Check if the file is valid, save it, load and split the data, add to the database, and remove the temporary file
if file.filename != '' and file and allowed_file(file.filename):
file_path = save_file(file)
chunks = load_and_split_data(file_path)
db = get_vector_db()
db.add_documents(chunks)
db.persist()
os.remove(file_path)
return True
return False
query.py
このモジュールは、クエリの複数のバージョンを生成し、関連するドキュメントを取得し、コンテキストに基づいて回答を提供することで、ユーザークエリを処理します。
import os
from langchain_community.chat_models import ChatOllama
from langchain.prompts import ChatPromptTemplate, PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain.retrievers.multi_query import MultiQueryRetriever
from get_vector_db import get_vector_db
LLM_MODEL = os.getenv('LLM_MODEL', 'mistral')
# Function to get the prompt templates for generating alternative questions and answering based on context
def get_prompt():
QUERY_PROMPT = PromptTemplate(
input_variables=("question"),
template="""You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from
a vector database. By generating multiple perspectives on the user question, your
goal is to help the user overcome some of the limitations of the distance-based
similarity search. Provide these alternative questions separated by newlines.
Original question: {question}""",
)
template = """Answer the question based ONLY on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
return QUERY_PROMPT, prompt
# Main function to handle the query process
def query(input):
if input:
# Initialize the language model with the specified model name
llm = ChatOllama(model=LLM_MODEL)
# Get the vector database instance
db = get_vector_db()
# Get the prompt templates
QUERY_PROMPT, prompt = get_prompt()
# Set up the retriever to generate multiple queries using the language model and the query prompt
retriever = MultiQueryRetriever.from_llm(
db.as_retriever(),
llm,
prompt=QUERY_PROMPT
)
# Define the processing chain to retrieve context, generate the answer, and parse the output
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
response = chain.invoke(input)
return response
return None
get_vector_db.py
このモジュールは、ドキュメントの埋め込みの保存と取得に使用されるベクター データベース インスタンスを初期化して返します。
import os
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores.chroma import Chroma
CHROMA_PATH = os.getenv('CHROMA_PATH', 'chroma')
COLLECTION_NAME = os.getenv('COLLECTION_NAME', 'local-rag')
TEXT_EMBEDDING_MODEL = os.getenv('TEXT_EMBEDDING_MODEL', 'nomic-embed-text')
def get_vector_db():
embedding = OllamaEmbeddings(model=TEXT_EMBEDDING_MODEL,show_progress=True)
db = Chroma(
collection_name=COLLECTION_NAME,
persist_directory=CHROMA_PATH,
embedding_function=embedding
)
return db
アプリを実行してください!
作成する .env 環境変数を保存するファイル:
TEMP_FOLDER = './_temp'
CHROMA_PATH = 'chroma'
COLLECTION_NAME = 'local-rag'
LLM_MODEL = 'mistral'
TEXT_EMBEDDING_MODEL = 'nomic-embed-text'
実行 app.py アプリケーション サーバーを起動するためのファイル:
$ python3 app.py
サーバーが稼働したら、次のエンドポイントへのリクエストを開始できます。
- PDF ファイルを埋め込むコマンドの例 (例: resume.pdf):
$ curl --request POST \
--url http://localhost:8080/embed \
--header 'Content-Type: multipart/form-data' \
--form file=@/Users/nassermaronie/Documents/Nasser-resume.pdf
# Response
{
"message": "File embedded successfully"
}
- モデルに質問するコマンドの例:
$ curl --request POST \
--url http://localhost:8080/query \
--header 'Content-Type: application/json' \
--data '{ "query": "Who is Nasser?" }'
# Response
{
"message": "Nasser Maronie is a Full Stack Developer with experience in web and mobile app development. He has worked as a Lead Full Stack Engineer at Ulventech, a Senior Full Stack Engineer at Speedoc, a Senior Frontend Engineer at Irvins, and a Software Engineer at Tokopedia. His tech stacks include Typescript, ReactJS, VueJS, React Native, NodeJS, PHP, Golang, Python, MySQL, PostgresQL, MongoDB, Redis, AWS, Firebase, and Supabase. He has a Bachelor's degree in Information System from Universitas Amikom Yogyakarta."
}
結論
これらの手順に従うことで、ニーズに合わせてカスタマイズされた Python、Ollama、ChromaDB を使用して、カスタム ローカル RAG アプリを効果的に実行し、操作することができます。必要に応じて機能を調整および拡張し、アプリケーションの機能を強化します。
ローカル展開の機能を活用することで、機密情報を保護できるだけでなく、パフォーマンスと応答性も最適化できます。顧客とのやり取りを強化する場合でも、内部プロセスを合理化する場合でも、ローカルに展開された RAG アプリケーションは、要件に合わせて適応し、拡張できる柔軟性と堅牢性を提供します。
このリポジトリのソースコードを確認してください:
https://github.com/firstpersoncode/local-rag
楽しいコーディングを!
関連記事
- なぜショベルナイトは多くのカメオを作るのですか? 「私たちは面白いと思います」
- 「安全でないシャットダウン」が SSD のマッピング テーブルを静かに破壊する仕組み
- このホリデー シーズンに 30,000 ルピー未満で購入できる 43 インチ 4K テレビのベスト 5