
- OS
-
Windows、macOS、iPhone、iPad、Android
- ブランド
-
マイクロソフト
- 価格
-
100ドル/年
- 開発者
-
マイクロソフト
- 無料トライアル
-
1ヶ月
Microsoft 365 には、最大 5 台のデバイスで Word、Excel、PowerPoint などの Office アプリ、1 TB の OneDrive ストレージなどへのアクセスが含まれています。
無効な値、空白のエントリ、重複などの問題がある乱雑な Excel スプレッドシートがある場合、それをクリーンアップするには何時間も費やす必要があると考えるかもしれません。代わりに Python を使用してこれらの手順を自動化できます。その方法は次のとおりです。
Python環境のセットアップ
必要なパッケージのインストール

Python 環境をまだセットアップしていない場合は、簡単にセットアップできます。 Windows を使用している場合は、Windows Subsystem for Linux (WSL) を使用することをお勧めします。 Python チュートリアルは Linux 環境、または少なくとも Unix に似た環境を想定する傾向があり、パス名などを翻訳する必要がないため、他のチュートリアルに沿って進めるのが簡単になります。
WSL がインストールされていない場合は、インストールする必要があります。
システム上に別の種類の環境も必要になる場合があります。 Python は、ほとんどすべての主要な Linux ディストリビューションを含む多くのシステムに含まれていますが、独自のプログラムというよりは、スクリプトやその他の付属ソフトウェアを実行することを目的としています。 OS がソフトウェアを更新する速度によっては、Python のバージョンが古い場合があります。
Python 上にいくつかのライブラリをインストールする必要もあります。
Python パッケージをインストールできる環境はいくつかありますが、私のお気に入りは Pixi です。
Linux、macOS、または WSL ターミナル ウィンドウで、次のように入力します。
curl -fsSL https://pixi.sh/install.sh | shこれにより、Pixi がマシンにインストールされます。
Pixi がインストールされていると、パッケージ用の環境を作成することも、パッケージをグローバルにインストールすることもできます。これらのツールをすぐに使えるため、このプロジェクトにはおそらくこれがより良い選択肢となるでしょう。
私たちが使用する主なパッケージは pandas ですが、このプロジェクトでは他のパッケージも必要になります。 NumPy は、Python を使用した数値計算の基盤です。 Jupyter ノートブックもインストールしたいと思います。これにより、Python コードをグラフィカルに実行できるようになり、後で調べることができるようになります。 IPython も似ていますが、ターミナルから動作します。
これらのツールをグローバル環境にインストールしましょう
pixi global install numpy pandas jupyter ipython
Python にデータを取り込む
環境がインストールされたら、乱雑なスプレッドシートの整理を開始できます。
この例では、特に乱雑なデータをクリーンアップする方法を学習するために、Kaggle で見つけたデータセットの修正バージョンを使用します。データが欠落していたり、「エラー」や用語が矛盾していたりするなど、多くの問題があります。元々は .csv ファイルでしたが、パンダが Excel ファイルをどのように処理できるかを示すために、LibreOffice を使用して Excel ファイルとして保存しました。
Jupyter を起動します。
jupyter notebookこれにより、Web ブラウザが開きます。Windows で WSL を使用していない場合は、Web ブラウザが開きます。エラーメッセージを取り除くにはコマンドラインを変更する必要があります
jupyter notebook –no-browserWeb ブラウザでリンクの 1 つを開きます。
私は通常、これをすべて回避するためにシェル エイリアスを使用します。
次に、新しいノートブックを作成し、カーネルとして Python を使用します。
私はヘッダーと説明文を Markdown セルとして配置するのが好きです。
最初のコードセルでは、使用するライブラリをインポートします。
import numpy as np
import pandas as pd次に、乱雑なデータセットを読み取ります
cafe = pd.read_excel('/path/to/messy_data.xlsx')データセットを調べることで、問題をよく理解できるようになります。
cafe.head() 欠損値の削除
見逃すことはありません
データセットをクリーンアップする最も簡単な方法は、欠損値を削除することです。 Pandas DataFrame には、それを行うための組み込みメソッド、dropna があります。データ変数をこのメソッドに設定すると、その場で DataFrame が編集されます。
cafe = cafe.dropna()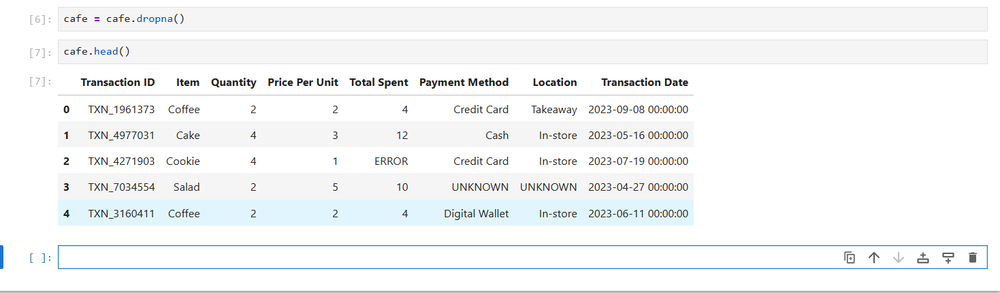
重複したエントリを削除する
データを二重にしないでください
次に、重複するエントリを削除します。 Pandas には、dropna と同様に機能する、drop_duplicates という組み込みメソッドがあります。
cafe = cafe.drop_duplicates()
これにより、データフレームが再度編集され、重複したエントリが削除されます。
列の変更
無効な値を削除する
まだ問題がいくつかあります。これらの列の多くのエントリには、「ERROR」または「UNKNOWN」のような文字が表示されます。おそらく私たちはそれらを望んでいないでしょう。
それらを取り除くのは簡単です。まず、フィルタリングする列の配列を作成します。
columns = ('Item','Quantity','Price Per Unit','Total Spent','Payment Method', 'Location', 'Transaction Date')次に、列を調べて「ERROR」または「UNKNOWN」を含むフィールドを削除する for ループを作成します。
for i in columns:
cafe = cafe(cafe(i) != "ERROR")
cafe = cafe(cafe(i) != "UNKNOWN")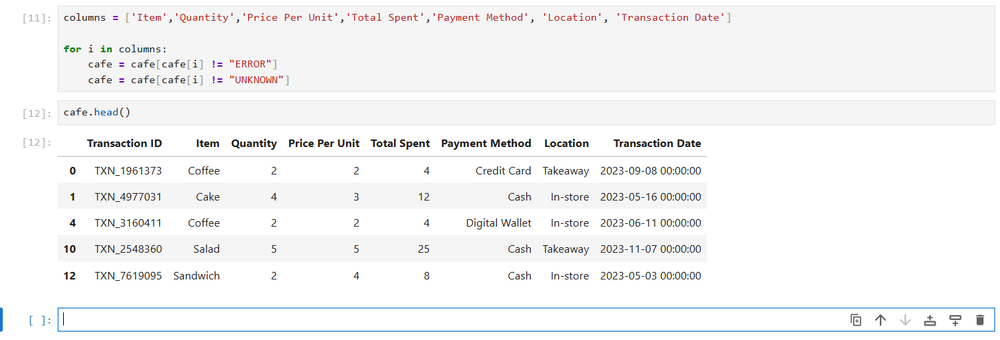
Python ループ内のステートメントはインデントする必要があり、Python では 4 つのスペースがインデントとしてカウントされます。
このループは、「ERROR」または「UNKNOWN」に等しくない列内のすべての値を選択し、それを所定の位置に保存します。
必ず head メソッドまたは tail メソッドを使用して DataFrame を調べて、変更の効果を確認してください。望ましくない動作が行われた場合は、元のデータをリロードして再試行できます。
これにより、検索と置換操作の実行も含め、Excel でこれらすべてを実行する必要があった時間を大幅に節約できました。
data.head() コマンドを再度実行して結果を確認できます。
データを Excel スプレッドシートに戻す
pandas DataFrame を Excel に変換するのは簡単です
データが消去されたので、Excel スプレッドシートに保存し直すことができます。 DataFrame の to_excel メソッドを使用できます
data.to_excel('/path/to/cleaned_data.xlsx') Python で Excel データをクリーンアップするのは簡単です
Python と少しの pandas の学習に少しの時間を費やすことで、スプレッドシートを個別に編集するために無駄に費やされる可能性のある時間を節約できます。 Python と Excel などのスプレッドシートは良い組み合わせです。Excel はデータの編集と書式設定に使用され、Python はより強力な分析情報のクリーニングと抽出に使用されます。
Windows、macOS、iPhone、iPad、Android
マイクロソフト
100ドル/年
マイクロソフト
1ヶ月
Microsoft 365 には、最大 5 台のデバイスで Word、Excel、PowerPoint などの Office アプリ、1 TB の OneDrive ストレージなどへのアクセスが含まれています。
このテーマについてさらに詳しく知りたい方は以下をご覧ください