多くの人は VS Code のような IDE や Vim のような通常のエディタを使用しますが、データ サイエンスや統計の仕事では、別のものが必要です。データセットの探索に IPython と Jupyter ノートブックを使用する理由は次のとおりです。
探索的プログラミング
IPython と Jupyter でデータを探索できる

IPython と Jupyter は、標準のスクリプトや IDE ワークフローとは異なるものを提供します。これらは対話型プログラミング ツールです。コードを入力すると、何が起こるかを即座に確認できます。スクリプトやプログラムを作成して実行する必要はありません。
これにより、新しいスタイルの開発への扉が開かれます。目標を念頭に置く代わりに、さまざまなアプローチを試すことができます。統計とデータ サイエンスがノートブックを採用するようになった理由の 1 つは、これらの分野が IPython や Jupyter が奨励する探索的なスタイルに適しているためです。データセットを調べている場合、そこに何が含まれているかについてはおそらくわからないでしょう。それを要約してグラフ化できれば、それを使って何ができるかがより明確になります。
IPython
より優れたインタラクティブな Python インタープリター

標準の Python インタープリターは、アイデアをテストしたり言語を学習したりするのに役立ちますが、多用しようとすると制限に遭遇します。標準の Python インタープリターに欠けている大きな点の 1 つは、タブ補完です。また、すでに実行したコードを再実行することも困難です。
IPython は大きな助けになります。タブ補完も含まれます。 Tab キーを押すだけで、IPython が関数や変数名などを入力します。履歴内を前後に移動したり、以前に入力したコマンドを検索したりすることもできます。これは、GNU Readline ライブラリを使用して、最新の Linux シェルと同じように機能します。
もう 1 つの便利な機能は、組み込みの「マジック」コマンドです。これらはパーセント記号 (%) で始まります。便利なマジック コマンドの 1 つは、「timeit」コマンドです。
まず、NumPy で 10 x 3 の配列 (X とします) を生成し、ランダムに生成された 10 個の数値の配列 (y とします) を生成することで説明します。
import numpy as np
rng = np.random.default_rng()
X = rng.random((10,3))
y = rng.random(10)次に、最小二乗解を計算して時間を計測します。
%timeit np.linalg.lstsq(X,y)実行にかかった時間が返されます。

この場合、これは小さなマトリックスではありますが、約 12 マイクロ秒かかり、かなり高速です。大きいものはさらに時間がかかる可能性があります:
X = rng.random((500,3))
y = rng.random(500)
%timeit np.linalg.lstsq(X,y)結果は約 22 マイクロ秒になります。これは大規模な線形システムとしては依然として高速です。
ジュピター
テキスト、コード、グラフィックを組み合わせる
IPython は Python 用の優れた対話型ターミナル プログラムですが、Jupyter はそれを次のレベルに引き上げます。 Jupyter はインタラクティブなノートブック プログラムです。 Jupyter を使用すると、コード、テキスト、インライン プロットを混在させることができます。これは、伝説的なコンピューター科学者ドナルド・クヌースが作った用語である「リテラシープログラミング」の一種です。
Jupyter ノートブックは、Mathematica などのプログラムのノートブック インターフェイスに似ています。ノートブックは、コードまたはマークダウン テキストを含めることができるセルから構築されます。 Jupyter はもともと IPython から派生したものですが、R、Julia、Scala などの他のプログラミング言語も使用できます。
以下は、Jupyter ノートブックの作成方法を示す Rob Mulla によるスクリーンキャストです。
Jupyter ノートブックの最大の特徴は永続性です。 Python を使用してデータセットを探索でき、データセットに戻ったときに、自分が何をしたかを思い出すことができます。
どちらをいつ使用するか
探索と永続性
IPython と Jupyter の両方には明確なユースケースがいくつかあります。簡単な実験のために、IPython を見てみましょう。私はバックグラウンドターミナルで実行したままにすることがよくあります。 NumPy、SymPy、その他の数学 Python ライブラリを使用して Pixi 環境を作成し、究極の卓上電卓を提供しました。
IPython は、後で参照する必要のない簡単な計算や使い捨ての計算に便利ですが、Jupyter は、戻ってきたり、他の人と共有したりするデータの探索に役立ちます。私はすでに、Jupyter ノートブックで独自の統計調査をいくつか GitHub アカウントにアップロードしました。
Vim は今でも、通常のスクリプトや設定ファイルの微調整に使用するエディターです。
典型的な統計ワークフロー
すべてをまとめると
Jupyter ノートブックを開いて簡単に説明します。 Jupyter はすでに「stats」というディレクトリにインストールされています。 Pixi の環境は単なるディレクトリです。これを再現可能な環境で実証したいと思います。ノートブックを GitHub リポジトリにアップロードしました。
Jupyter サーバーを起動します。
jupyter notebook新しいノートを作成します。ニューヨーク市のレストランでウェイターが取得した、請求額の合計、チップ、パーティーの客の数、喫煙者の有無を記録した、事前定義されたデータ セットを調べます。
使用するライブラリを含むセルを作成します。
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_theme()
from scipy import stats
import statsmodels.api as sm
import statsmodels.formula.api as smf
%matplotlib inlineこれにより、NumPy、pandas、Seaborn、SciPy の統計サブモジュール、statsmodels、およびその式 API がインポートされ、プロットを別のウィンドウで開くのではなく Jupyter ノートブックに挿入するように matplotlib に指示されます。
ライブラリをインポートすると、Seaborn からヒント データベースをロードできます。このデータベースには、主にプロット用のデータセットが組み込まれています。これは pandas DataFrame として保存されます。
tips = sns.load_dataset('tips')データセットの上部を見てみましょう。
tips.head()
次に、数値列の説明的な統計を取得します。これには、平均、標準偏差、最小値、下位四分位 (25 パーセンタイル)、中間値または中央値、および上位四分位 (75 パーセンタイル) が含まれます。
tips.describe()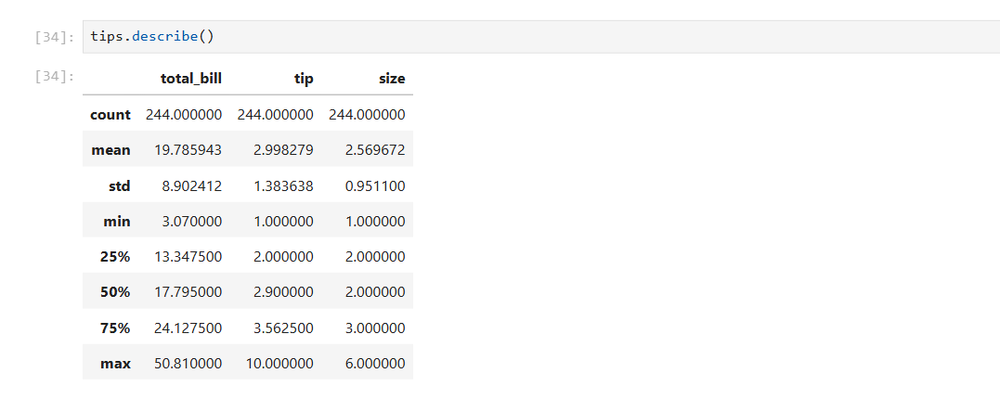
次に、請求総額の分布を見ていきたいと思います。
sns.displot(x='total_bill',data=tips)
そしてヒント:
sns.displot(x='total_bill',data=tips)
次に、チップと請求額の散布図を見てみましょう。
sns.relplot(x='total_bill',y='tip',data=tips)
散布図上に回帰直線をプロットできます。
sns.regplot(x='total_bill',y='tip',data=tips)線が上向きに傾いているため、正の線形関係があるように見えます。 statsmodels を使用して、R で普及した数式表記を使用して古典的な方程式 y = mx + b に代入する値を取得する必要があります。
results = smf.ols('tip ~ total_bill',data=tips).fit()
results.summary()
y 切片と傾き (m) の値 (この場合は合計請求額) が表の一番左の列にリストされています。
ボトムアップでプログラムを構築する
インタラクティブ プログラミングの最も優れた点は、何もない状態から始めて、最終的には完全な分析を完了できることです。これは、探索を通じてプログラムを構築し、その結果を他の人と共有できる、一種のボトムアップ プログラミングです。
このテーマについてさらに詳しく知りたい方は以下をご覧ください