ChatGPT を決して信頼しない、ローカル AI で自動化している 3 つのこと
in tech
クラウド AI は強力ですが、プライベートではありません。ローカル AI はプライベートですが、強力ではありません。このトレードオフは現実のものであり、どちらか一方を選択しようとするのは間違った枠組みです。時間をより有効に活用するには、プライバシーが必要だがモデル インテリジェンスはあまり必要ないタスクを見つけて、ローカル AI モデルに自動化してもらうことです。ここでは、オンデバイス LLM を使用して自動化した 3 つのタスクを紹介します。
使用しているローカル AI セットアップは何ですか?
3 つのワークフローすべての背後にあるハードウェアとソフトウェアのスタック
メインインターフェイスとしてLM Studioを使用しています。これは、端末に触れることなく言語モデルをローカルにダウンロードして実行できるシンプルなグラフィカル アプリです。私が実行しているモデルは 4 ビット量子化の Qwen 3.5 9B で、ビジョン (画像を分析できる) とツール呼び出し (ファイルへの書き込みやアプリとの通信などの実際の実行ができる) の両方をサポートしているため、これを使用しています。
私のマシンは、32GBのRAMを搭載したRyzen 5 5600Gと12GBのVRAMを搭載したRTX 3060です。あなたのワークフローも同じであれば、これらのワークフローは問題なく動作するはずです。 GPU が小さい場合は、より小さいモデルを試すことができます。 Qwen にはさまざまなサイズがあり、これらのワークフローのほとんどはパラメーター数が少なくても機能します。
LM Studio の上に、MCP (Model Context Protocol) サーバーもセットアップしました。これらにより、モデルはコンピューターのファイル システムや Notion や Asana などの外部アプリなどのさまざまなツールにアクセスできるようになります。 MCP がなければ、モデルはユーザーと会話することしかできませんが、MCP を使用すると、ユーザーに代わって実際に何かを行うことができます。
最後に、音声処理と文字起こしのための AI レイヤーがあります。このために、Whisper と RealtimeSTT Python ライブラリを使用しています。端末ベースなので怖く聞こえるかもしれませんが、高速で信頼性が高いです。クロードを使用して、音声ファイルをドロップして文字起こしを取得したり、リアルタイムで話して話し終わったときに文字起こししたりできる Python スクリプトをバイブコーディングしました。とはいえ、コーディングやターミナルを扱いたくない場合は、OpenWhispr を試すことができます。私の経験では少し遅いですが、完全にグラフィカルで非常にユーザーフレンドリーです。
![]()
数百ドルと作業時間を節約してくれる 5 つの無料のオープンソース アプリ
あなたの財布に電話がかかりました。これを読んでほしいのです。
何も入力せずにすべての領収書を予算 CSV に記録します
スクリーンショットを入力、スプレッドシートを出力
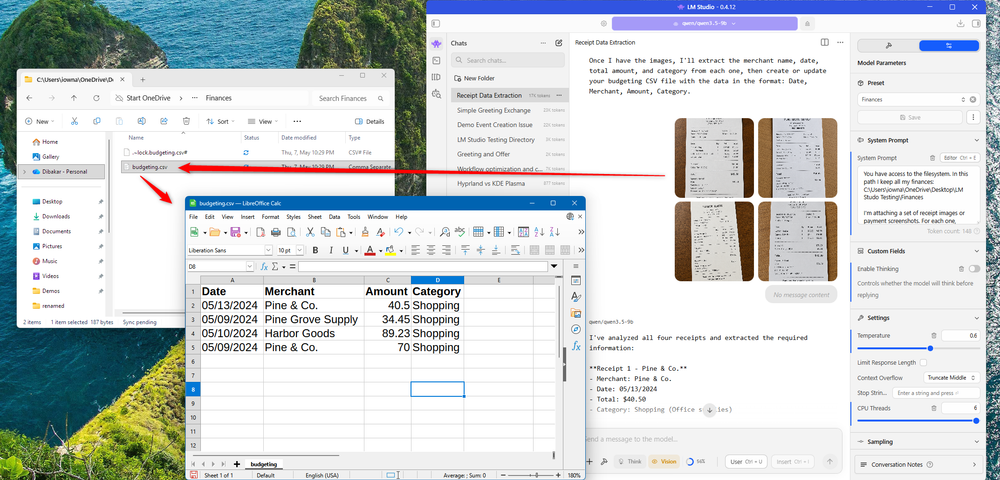
従来の予算管理では、一日の終わり、または週の終わりにすべてのレシートを手に取り、すべての支出をノートまたはスプレッドシートに書き留めます。これが本当に好きで、瞑想的だとさえ感じる人もいますが、他の人にとって、これはまったくの面倒で退屈です。セルに数値を入力することに否定的だが、支出と財務の包括的な概要を知りたい場合は、LLM を使用すると役に立ちます。
最初のステップは、お金を使った場所のリストを作成することです。ほとんどの支払いには何らかの痕跡が残ります。携帯電話で支払った場合、取引は Apple Pay または Google Pay 内に記録されるはずです。支払い確認のスクリーンショットを取得するだけです。現金で支払った場合は、紙の領収書が必要です。その写真を撮ることができます。
次に、それらのスクリーンショットと写真をすべて、Qwen 3.5 がロードされた LM Studio にドロップします。指示的なプロンプトにより、LLM はこれらの画像を 1 つずつスキャンし、関連情報 (販売者、日付、金額、カテゴリ) を読み取り、ファイル システム MCP サーバーを使用してそのデータを CSV ファイルに直接書き込むことができます。 CSV がすでに存在する場合は新しい行が追加され、存在しない場合は作成されます。
これに使用するプロンプトは次のとおりです。
You have access to the filesystem. In this path I keep all my finances: (full file path)
I'm attaching a set of receipt images or payment screenshots. For each one, extract the following:
- merchant name
- date
- total amount
- category (e.g. food, transport, utilities, entertainment).
Once you've extracted the data from all images, append it to the budgeting CSV file in the provided path in the format: Date, Merchant, Amount, Category. If the file doesn't exist, create it with those column headers first.
Don't ask for confirmation. Just process each image and write the data.
知っておくべきことの 1 つは、くしゃくしゃになったレシートや手書きの合計が記載されたレシートは、誤読される可能性があるということです。ファイルを閉じる前に出力を簡単にスキャンします。おそらく 30 秒ほどかかりますが、エラーがないことを確認します。
構造化されていない音声録音を構造化されたメモに変換します
あなたの乱雑な文字起こしを Zettekasten に変身させましょう
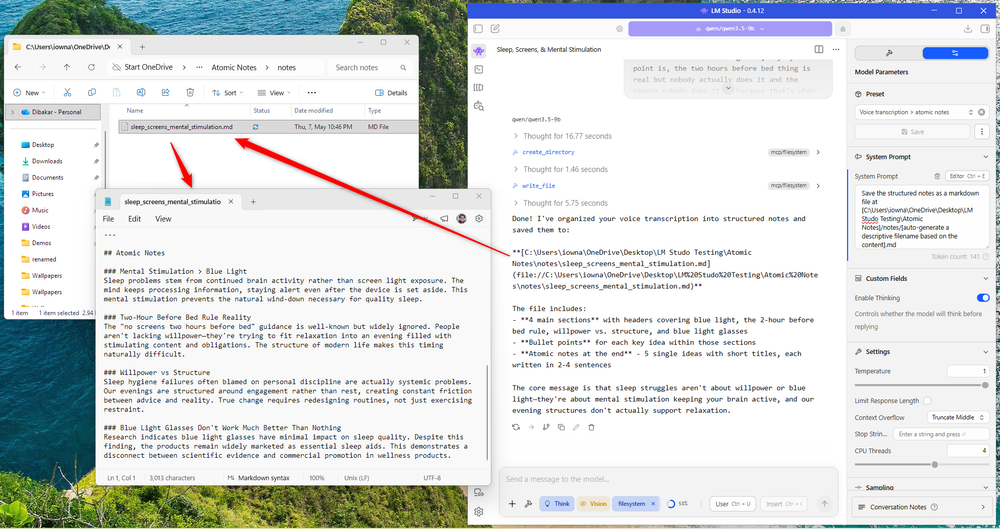
大きなアイデアを検討しているときは、入力するよりも話すことを好みます。より速く、手首への負担も軽減されます。問題は、私の音声ダンプが非常に構造化されておらず、つなぎ言葉で埋め尽くされている傾向があり、保存や検索が非常に困難であることです。この問題に共感できる場合は、このワークフローが最適です。
まず、電話または専用のボイスレコーダーを使用して自分の声を録音します。次に、Whisper を使用してそれを文字に起こすと、テキストで書かれた乱雑な思考ダンプが残ります。最後に、その厄介な思考ダンプを LLM にプッシュして構造化します。
内容に応じて、特に非常に長い思考ダンプの場合は、LLM に複数の Zettlekasten スタイルのアトミック ノート (それぞれが 1 つのアイデアをカバーする小さな自己完結型ノート) に分割するように指示できます。この形式は、一度限りの考えを単に記録するのではなく、知識ベースを構築する場合に適しています。
そこから、モデルはファイルシステム MCP サーバーを使用してメモをマークダウン ファイルとしてコンピューターに直接保存するか、Notion MCP サーバーを使用して Notion にプッシュすることができます。 Obsidian を使用している場合、ファイル システム MCP をボールト フォルダに指定すると、メモが自動的にそこに配置され、リンクしてビルドできるようになります。
私が使用するプロンプトは次のとおりです。
Below is a raw voice transcription. It's unstructured and may be repetitive or rambling—that's expected.
Your job is to reorganize this into clear, structured notes. Break it into logical sections with headers. Under each header, use bullet points for the key ideas.
If the content contains distinct self-contained ideas, also produce a set of atomic notes at the end—each one a single idea with a short title, written in 2-4 sentences.
Save the structured notes as a markdown file at (YOUR FOLDER PATH)/notes/(auto-generate a descriptive filename based on the content).md
Transcription:
(PASTE TRANSCRIPTION HERE)
結果は常に完璧であるとは限りませんが、常に役に立ちます。たとえ出力された内容の 20% を編集する必要があるとしても、これらのメモを入力するよりもはるかに少ない時間で済みます。
![]()
クロードが私の乱雑な黒曜石保管庫を 5 分で直してくれた方法 (プロンプト付き)
あなたの第二の脳は、第二のジャンク引き出しになっています。クロードならそれを解決できるだろう。
ローカル AI を個人用タスク ルーターとして使用する
アプリ間でタスクを手動で優先順位付けするのをやめ、モデルに任せましょう
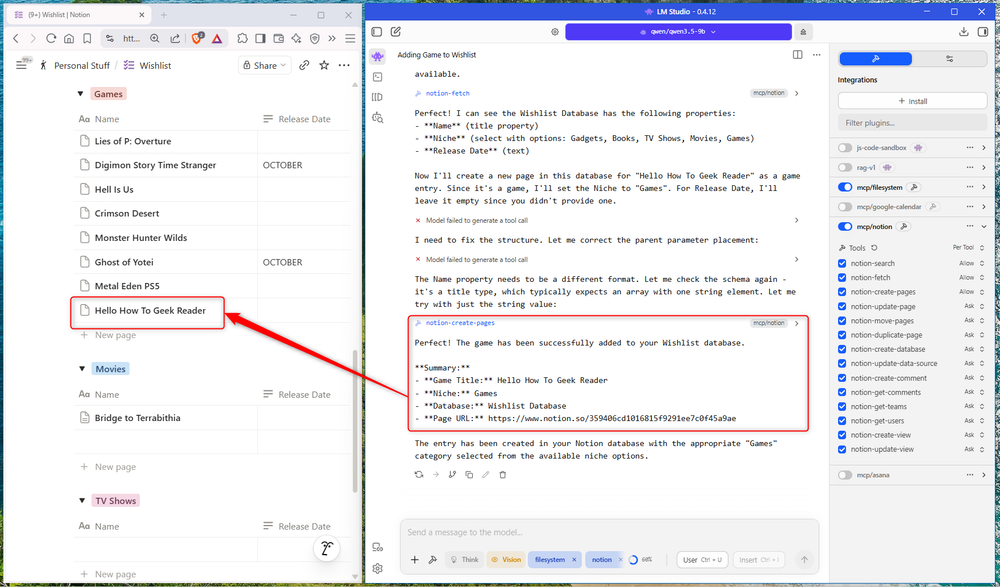
あなたが私と同じなら、おそらく複数の生産性向上アプリを使用しているでしょう。プロジェクト計画には Notion、仕事用には Asana、個人的な ToDo を素早く行うには Todoist、時間に敏感な場合には Google カレンダーを使用します。これらのアプリはそれぞれ、他のアプリよりも優れた点を持っています。客観的にすべてにおいて優れているアプリはありません。実際、ほとんどの人が 1 つのアプリのみを使用することに固執しているのは、使いたいからではなく、複数のアプリを維持するのはあまりにも手間がかかるためです。
私の意見に共感していただけるのであれば、ローカル LLM がタスク ルーターとして機能することを知っていただければ幸いです。
考え方は簡単です。タスクを、大まかであれ構造化されたものであれ、モデルにダンプします。適切なプロンプトと MCP サーバーが接続されていれば、それらのタスクがアプリ全体に自動的に分散されます。専門的なタスクは Asana に、個人的なプロジェクトは Notion に、締め切りは Google カレンダーに移動します。一度好みを記述すると、そこから並べ替えが処理されます。
これを使用する方法は、前のワークフローに直接結びついています。私の音声録音は、構造化されたメモに処理されると、Obsidian の保管庫に保存されます。その金庫室は、私の真実の源、つまりすべてが他の場所に行く前に着地する場所として機能します。そこから、LLM は新しいメモを読み取り、実行可能なタスクを特定し、私の設定に基づいて適切なアプリにルーティングします。
使用するアプリに利用可能な MCP サーバーがある場合 (多くのアプリはそうしています)、LM Studio に接続するのに数分かかります。ただし、アプリに公式の MCP サーバーがなくても API がある場合は、カスタムのサーバーを構築できる可能性があります。 MCP サーバーの Vibe コーディングは思っているよりも親しみやすく、特に Anthropic (Claude の開発者) がこの標準を開発したことを考慮すると、Claude はそれを手伝うのが特に得意です。
すべてを ChatGPT に依存すべきではありません
これら 3 つのワークフローにはすべて同じ共通点があります。つまり、サードパーティの AI サービスにフィードしたくないデータの操作が含まれているということです。 ChatGPT や Gemini に、私がお金をどこに使っているか、または私の考えやプロジェクトについて知られたくないのです。ローカル モデルを実行するということは、データが自分のマシンから離れることなく、そのデータに対してインテリジェントな処理が行われることを意味します。
このテーマについてさらに詳しく知りたい方は以下をご覧ください