- 広告付きの定期購入
-
有料プランでは広告はありません
- 価格
-
月額 11.99 ドルから、学生の場合は月額 5.99 ドルから
コンピュータに向かうときはいつも、Spotify がバックグラウンドで動作しているようです。 Spotify の曲に関するデータが入手可能になったので、ヒット曲に共通する特徴があるかどうかを確認したいと思いました。私は Spotify を使用して、ヒット曲のモデルを構築できるかどうかを確認しました。
データセットの取得
Kaggle が助けてくれます
音楽データを調べるには、データセットを見つける必要があります。他の多くのテクノロジー企業と同様に、Spotify は開発者がデータを利用できるようにしています。開発者アカウントにサインアップして、Spotify のデータを収集するための API を学ぶこともできましたが、他の人がそれを私に代わって行い、データセットを Kaggle に投稿しました。
私は、Joakim Arvidsson が編集した 30,000 以上のヒット曲のデータセットの 1 つをダウンロードしました。 Kaggle コマンドライン クライアントを使用してマシンにダウンロードしました。
kaggle datasets download joebeachcapital/30000-spotify-songs分析を保存するために Jupyter ノートブックをセットアップしました。分析は GitHub アカウントで表示できます。
次に、標準の Python 統計ライブラリをセルにインポートしました。
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_theme()
%matplotlib inline
import matplotlib.pyplot as plt
import statsmodels.formula.api as smf
import statsmodels.api as sm
from scipy import statsこの部分では、一般的な数値解析および線形代数ライブラリである NumPy をインポートします。このライブラリには、いくつかの一般的な統計関数も含まれています。 pandas は、「DataFrames」内の表形式のデータを操作するためのライブラリです。 Seaborn は、一般的な統計視覚化のためのライブラリです。 sns.set_theme() 関数はデフォルトのテーマを設定します。 「%matplotlib inline」は、別のウィンドウではなく Jupyter ノートブックにプロットをレンダリングするように Jupyter に指示する「魔法の」コマンドです。次の行では、Matplotlib ライブラリをインポートして追加のプロットを作成します。 statsmodels 行は、使用するモデルを作成するための statsmodels とその式 API の両方をインポートします。最後に、統計ルーチンを SciPy ライブラリからメインの Python 名前空間にインポートします。
次に、データを pandas DataFrame にインポートしたいと思いました。
spotify = pd.read_csv('data/spotify_songs.csv') データを調べる
土地の状況を把握する
インポートされたデータを使用して、それを探索して視覚化したいと考えました。まず、データの最初の数行を調べて、どのようにレイアウトされているかを確認しました。
sns.head()
これらの見出しは何を意味するのでしょうか? Kaggle データセットには、列を説明する「データ カード」が含まれています。 「track_id」などの一部は一意の番号ですが、「track_title」、「track_artist」、「playlist_name」、「playlist_genre」などは一目瞭然のように見えます。その他は Spotify によって定義されます。 「音響性」は、アコースティックギターなどのアコースティックサウンドがトラックをどの程度支配しているかを測定します。 「ダンサビリティ」は、トラックがどれだけ「ダンサブル」であるかを測定します。 「ラウドネス」は、トラックがどのくらい大きく聞こえるかを測定します。 「インストゥルメンタルネス」は、その曲がどの程度「インストゥルメンタル」であるか、またはその中にどれだけ歌が含まれているかを測定します。 「ライブネス」は、聴衆の騒音を含め、トラックがどの程度ライブコンサートのように聞こえるかを測定します。 「エネルギー」は、トラックがどれだけエキサイティングに聞こえるかを測定します。 「スピーチネス」は、トラック内の話し言葉の量を測定します。 「ヴァレンス」は、トラックがどの程度「ポジティブ」に聞こえるかを測定します。
ここで、いくつかの要約統計を見たいと思いました。 「describe」メソッドを使用しました。
spotify.describe()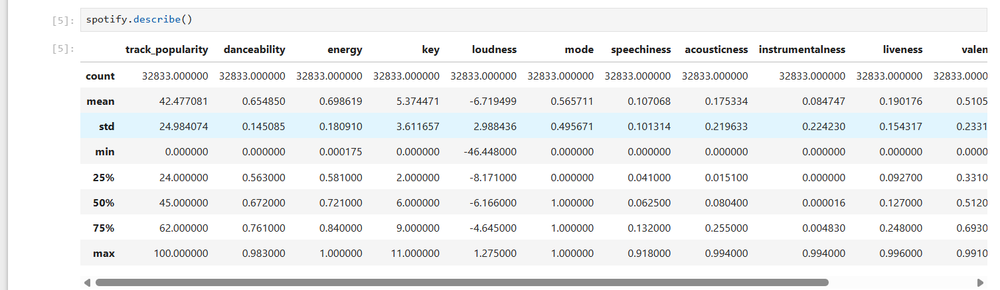
これにより、要素数、平均、中央値、サンプル標準偏差、最小値、下位四分位または 25 パーセンタイル、中央値、上位四分位または 75 パーセンタイル、各列の最大値など、いくつかの基本的な記述統計が計算されます。要素の数だけ見ると、かなり大きなデータセットです。
これらの数値を計算したら、分布を見てみましょう。多数の列を含むデータセットでは各列のヒストグラムをプロットするのに時間がかかることがありますが、パンダに 1 つのコマンドで各列のヒストグラムをプロットさせることができます。
spotify.hist()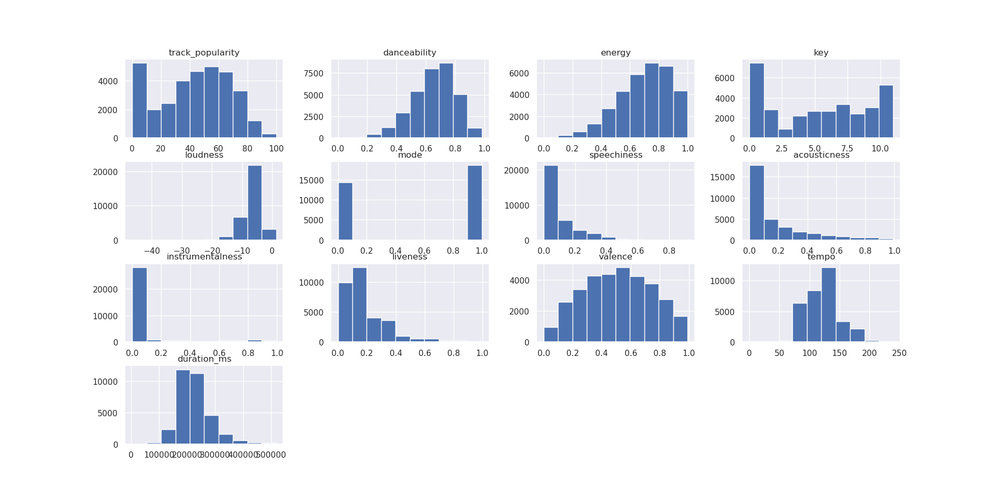
データセットの分布の多くがどちらかに偏っていることに気づきました。私が予測しようとしているトラックの人気には、ヒストグラムの左側にある 0 の高いバーからわかるように、まったく人気がないと思われるトラックがたくさんあります。
モデルの構築: 特性の追跡
ヒット曲は何でできているのでしょうか?
データをロードして視覚化を行った後、どの変数が人気に最も大きな影響を与えるかを確認したいと思いました。私の最初の試みは、statsmodels を使用して他の変数に対して通常の最小二乗回帰を実行することでした。 statsmodels の数式メソッドを使用しました。
results = smf.ols('track_popularity ~ danceability + energy + key + loudness + mode + speechiness + acousticness + instrumentalness + liveness + valence + tempo + duration_ms',data = spotify).fit()
results.summary()グラフにはモデルを当てはめようとする試みが示されていましたが、共線性の可能性、または値が同じ線上にあるため、数値結果が信頼できない可能性があるというメッセージが表示されました。
極端な結果にペナルティを与えるため、正規化回帰を試してみることにしました。
results = smf.ols('track_popularity ~ danceability + energy + key + loudness + mode + speechiness + acousticness + instrumentalness + liveness + valence + tempo + duration_ms',data = spotify).fit_regularized()同じ結果メソッドはありませんが、係数を確認するための params 属性があります。係数は、1 つの変数の変更が結果にどのような影響を与えるか、および正の関係があるのか負の関係があるのかを知ることができます。
results.params結果は次のとおりです。
Intercept 57.497818
danceability 6.867472
energy -21.567406
key 0.095799
loudness 1.123025
mode 1.183389
speechiness -5.345878
acousticness 6.543464
instrumentalness -12.618947
liveness -3.144802
valence 4.081272
tempo 0.064768
duration_ms -0.000032
dtype: float64係数に基づくと、人気に対する最大の否定的な予測因子は、エネルギー、言論性、および手段性です。より大きなポジティブな予測因子は、ダンサビリティ、ラウドネス、そしてヴァレンスであるようです。あなたのアコースティックセットが最後のオープンマイクで大ヒットした場合は、レコード契約を獲得しようとするかもしれません。インストゥルメンタル音楽を作成している場合は、おそらくすぐに本業を辞めたくないと思うでしょう。
モデルの構築: ジャンル
音楽の種類も重要
また、ジャンルが成功の予測因子であるかどうかも確認したいと思いました。そのためには、分散分析 (ANOVA) を使用します。まず、プレイリストのジャンル別の人気の箱ひげ図を作成しました。
sns.catplot(x='playlist_genre',y='track_popularity',kind='box',data=spotify)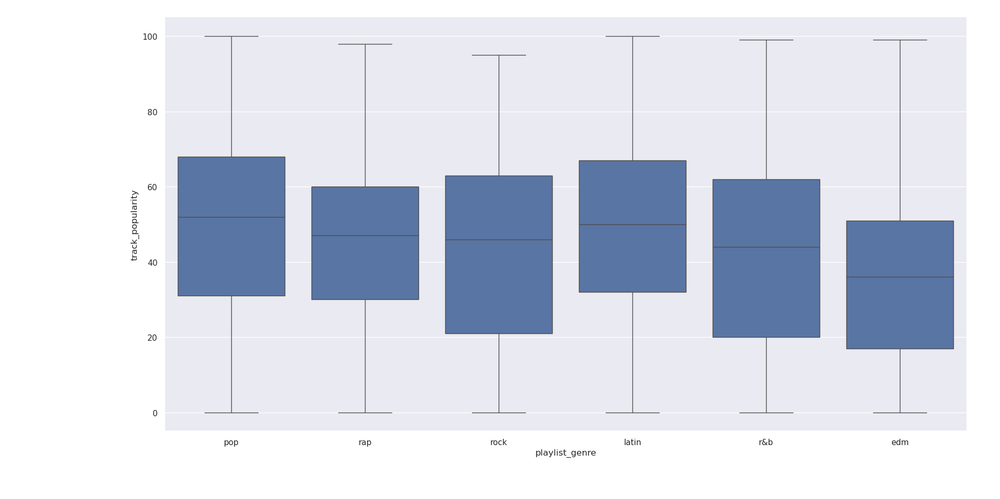
ボックスプロットは、プレイリストのジャンル間でトラックの人気に大きな違いがあることを示唆しているようです。今回はカテゴリを使用して、別の線形モデルを作成しました。
次に、この線形モデルを anova_lm メソッドで使用しました。
sm.stats.anova_lm(genre_lm)
p 値が非常に低いため、ジャンルが人気の重要な予測因子であることを意味します。ジャンルごとのトラックの人気の棒グラフを作成します。
sns.catplot(x='playlist_genre',y='track_popularity',kind='bar',data=spotify)
ヒット曲を出したい場合は、ラテンやポップスのプレイリストに参加するとよいでしょう。
ヒット作を予測できるかも知れません
音楽は主観的なものですが、おそらくいくつかの大まかな特徴を予測することができます。おそらく人々は、特定の音楽要素を特定の方法で好きなだけなのかもしれません。現在人気のあるジャンルの曲が大ヒットする可能性があります。しかし、音楽は常に数字に要約できるわけではありません。コードを使用して人間の経験を統計的に調査するのはやはり楽しいです。
有料プランでは広告はありません
月額 11.99 ドルから、学生の場合は月額 5.99 ドルから
このテーマについてさらに詳しく知りたい方は以下をご覧ください